How we scaled Robinhood’s brokerage system for greater reliability

Authors Edmond Wong and Nathan Ziebart are technical leads on Robinhood’s Brokerage Engineering Team. Explore opportunities to work with them at Robinhood’s careers page.
As we’ve grown, we’ve worked to find solutions that meet and exceed the needs of our growing customer base. In December 2019, our brokerage system received 100k requests per second at peak time, and in June 2020, that number rose to 750k requests per second. After experiencing a 7x load increase to the system during that six-month period, we’re now preparing all of our systems to meet the needs of high market volatility.
Last year, we set out to make our brokerage infrastructure horizontally scalable by sharding our singular database server into multiple independent instances. Our goal was to increase capacity, and also to give ourselves the ability to add more capacity in the future by adding more hardware.
Robinhood’s original brokerage trading system was built on a single database server with a dynamically scalable application server tier. This single database was not scalable and exposed us to gradual performance degradation during periods of high trading volume and market volatility.
Defining the Problem
In the past, a lot of our work on the brokerage system’s backend had focused on vertical scalability, increasing the number of application servers, caching, optimizing slow queries, upgrading database sizes or optimizing the application code. But with each iteration of optimizations, we saw diminishing returns, forcing us to come up with ever more creative — and complex — solutions to get more performance out of our single database.
We explored different options. We thought about migrating to an entirely new database, looking at solutions like Google’s Cloud Spanner, AWS’s DynamoDB, CitusDB, and CockroachDB, but found that these would probably require a more invasive rewrite of our core business logic, and data access layers. We love native PostgreSQL, but unfortunately, it just doesn’t scale horizontally beyond a single server.
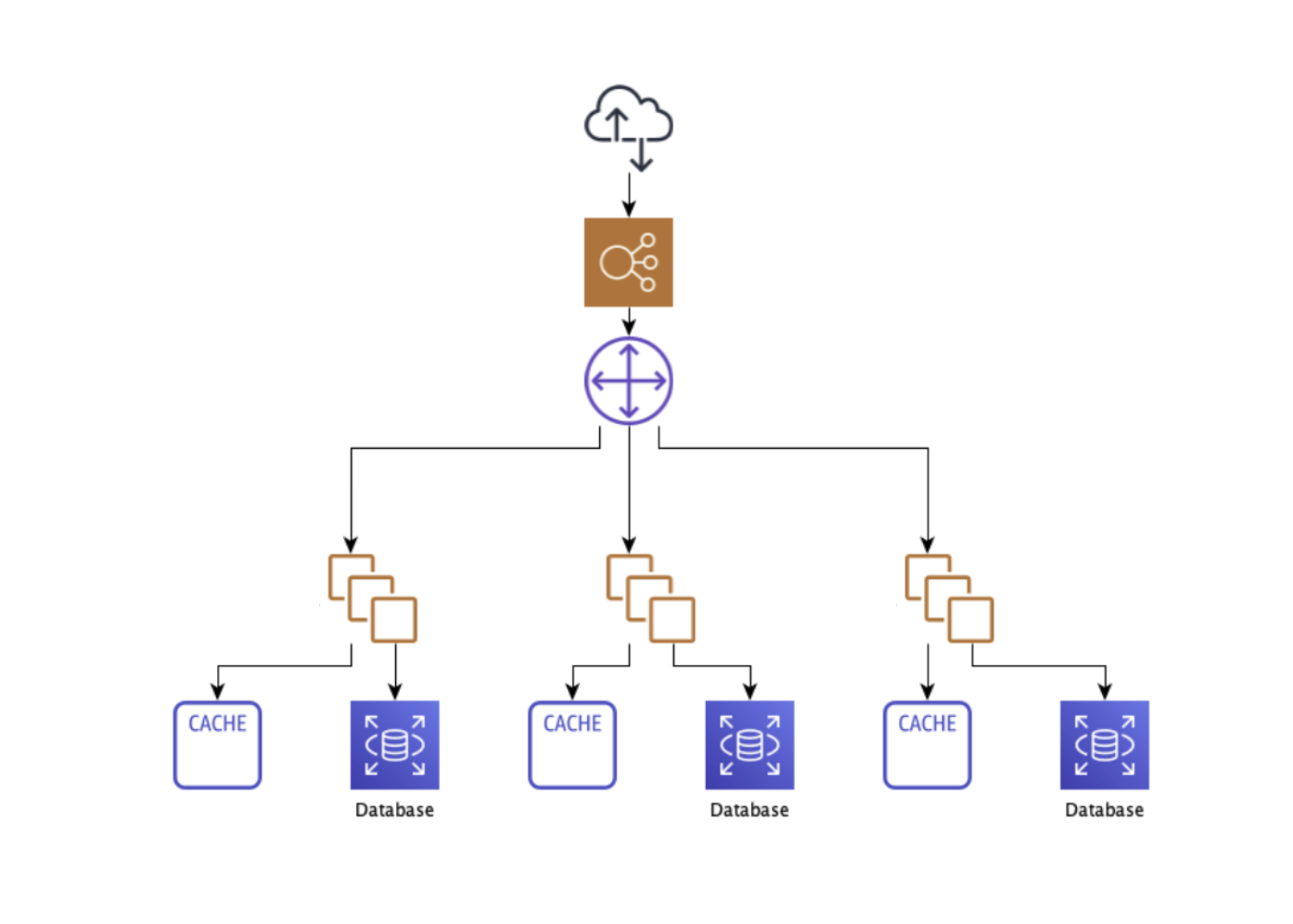
Horizontally Scaling For More Reliability
We landed on building a sharding system on top of PostgreSQL. The next step was to determine, where in our system the sharding should occur. The options were; could we divide the database, and keep our application layer unified?; or would we need to shard the whole system? System reliability is incredibly important to us, and we prioritize it when making difficult technical decisions. We decided to shard the system at the application level because it enabled us to increase reliability through service isolation, decreasing the blast radius of any future incidents. It also enables us to roll out new features to individual shards at a time, with minimal risk to the system at large.
The Technical Implementation
We applied the same principles and decision-making framework to the technical implementation that we used to select the solution. This required building a couple of sharding control layers that allowed our newly divided system to appear as one system, rather than independent shards.
- The Routing Layer: The first routing layer is a switchboard of sorts that handles routing an external API request to the correct shard. The request is routed to the corresponding shard for processing by inspecting and mapping the request to a user, which then maps to a specific shard. In the initial implementation, we made a synchronous API call to our shard mapping service to look up the shard ID on each request.
- The Aggregation Layer: We built this layer to act as an intermediary with internal API traffic. This layer enabled other services to query data without knowing which shard it lived in, by joining data from multiple shards.
- Kafka Message Streaming: We had to design a way for Kafka messages to be consumed by the correct shard. To do this, we have every shard consume all messages, but only process messages that correspond to users that exist in that shard. This might not be the most efficient method, but it saved us from building yet another proxy layer, and risk overcomplicating an already complex system. For specific high-throughput use cases, we would also create specific topics for individual shards to avoid the overhead of filtering messages in a unified topic.
Building the aggregation layer was particularly challenging, and a major part of making sure our sharded system worked with Robinhood’s current APIs. The data that needs to be returned for any given request could now reside in multiple shards, and we might not be able to determine which shard(s) the data lives in just by inspecting the request. We needed a system to aggregate what would have been multiple internal API calls to many shards into a single request, so we built a stateless service to fan out requests across shards and merge the results. Sometimes, this also involved paginating results across shards in order, which required developing a custom cursor format that included the individual cursor locations for each shard.
These solutions allowed us to maintain our data’s integrity, while also safeguarding the whole system. We could compartmentalize an issue before it could impact other parts of the backend infrastructure. Now, each shard has its own application servers, database, and deployment pipeline, and customers are assigned to shards using durable and cacheable mapping records. Ultimately, we can add more shards — theoretically an infinite number of them — as we grow.
We’re proud to have come a long way with this initiative. We had one shard at the beginning of 2020, three at the end of 2020, and now have 10, all individually capable of handling many hundreds of thousands of requests per second. Infrastructure failures might still rear their head in the future, but they’re now limited to one shard. This decentralized approach has increased our reliability as well as our scalability.
All investments involve risk and loss of principal is possible.
Robinhood Financial LLC (member SIPC), is a registered broker dealer. Robinhood Securities, LLC (member SIPC), provides brokerage clearing services. Robinhood Crypto, LLC provides crypto currency trading. All are subsidiaries of Robinhood Markets, Inc. (‘Robinhood’).
© 2021 Robinhood Markets, Inc.